Basic Data Structure
基础的数据结构和一些基本操作,及其 golang 语言的实现。
Array Link to heading
数组 是线性表数据结构。用一组连续存储空间,储存一组相同类型的数据。支持随机访问 O(1)。
低效插入和删除 O(n),需要数据搬移。优化:删除操作延后(JVM垃圾回收算法)。
Linked list Link to heading
链表 插入删除 O(1),随机访问O(n)。
单链表:插入删除时需要查找前驱节点 O(n)。
双向链表:插入删除时查找前驱结点 O(1)。
- 链表代码实现
- 单链表字符串回文判断
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表中间节点
Stack Link to heading
栈 后进先出,先进后出。入栈出栈 O(1)
顺序栈:数组。动态扩容(动态扩容数组,数据搬移O(n))
链式栈:链表。
- ArrayStack 实现
- LinkedListStack 实现
Queue Link to heading
队列 先进先出,后进后出。 入队出队O(1)
- 数组实现(数据搬移)
- 链表实现
- 循环链表数组实现
Skip list Link to heading
跳表 链表加多级索引的数据结构。查找 O(logn)。Redis 中有序集合 Sorted Set 用跳表实现。
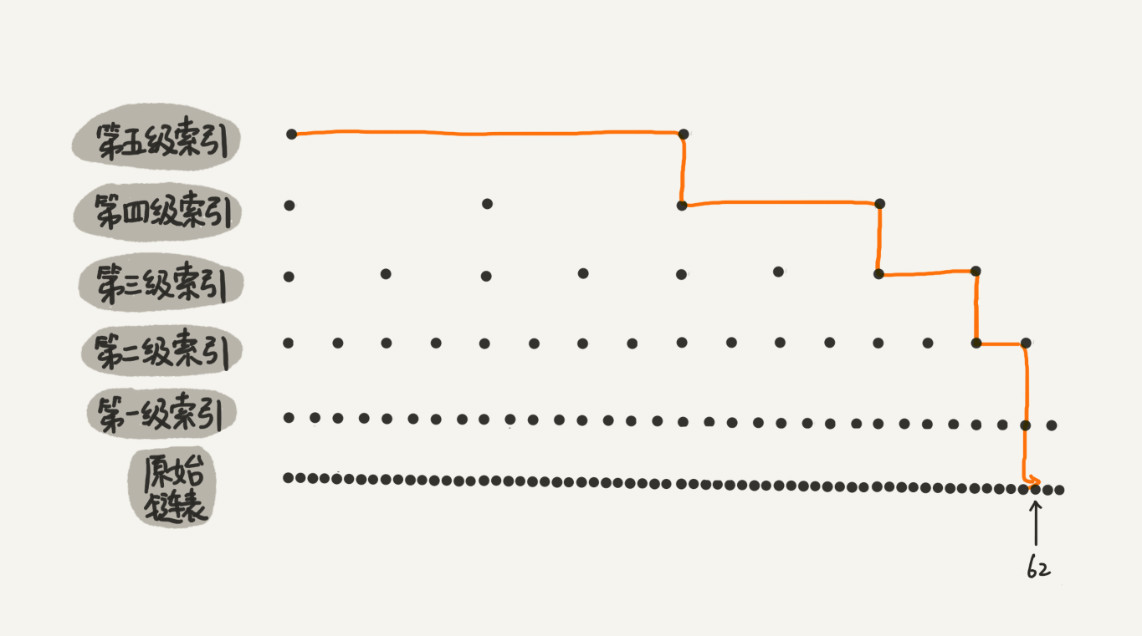
插入删除 O(logn)。 平衡性维护-随机函数。
- 实现
Hash Table Link to heading
散列表 通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。支持随机访问 O(1)。
散列函数。
装载因子 = 填入表中的元素个数 / 散列表的长度
解决散列冲突:
- 开放寻址法
优点:可以有效利用CPU缓存加快查询速度;便于序列化。
缺点:删除时不能直接删除,需要特使标记已删除的数据;冲突代价高。- 线性探测(ThreadLocalMap):当往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。(hash(key)+n)
- 二次探测:hash(key)+n^2
- 双重散列:使用多组散列函数(hash1(key),hash2(key),hash3(key))
- 链表法(LinkedHashMap)
优点:内存利用率高,链表节点不需要提前申请;大装载因子容忍度高。
缺点:CPU缓存不友好;由于要存储指针,存储小对象时内存消耗大。
动态扩容:避免一次性搬移大量数据。扩容时只申请新空间,新的数据插入新的散列表,同时将小部分老数据搬移至新散列表,将扩容消耗均摊至每次插入。
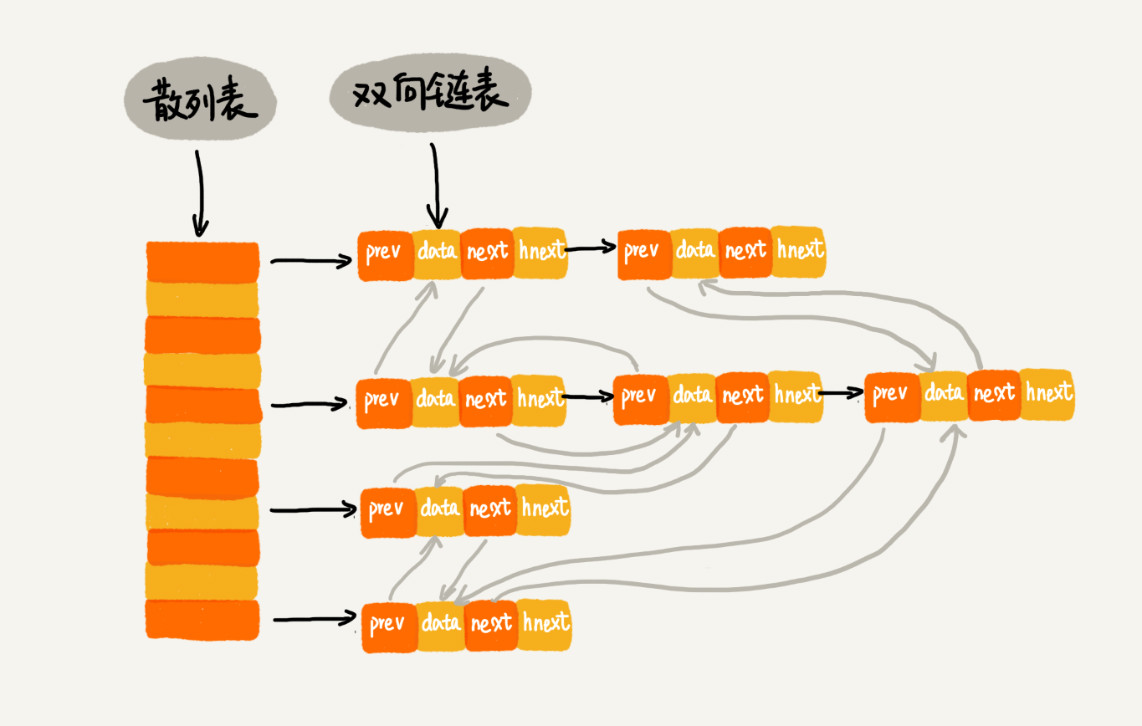
散列表+双向链表 查找删除添加 O(1):
LRU 缓存淘汰算法/Redis 有序集合/Java LinkedHashMap
散列表是通过链表法解决散列冲突的,所以每个结点会在两条链中。一个链是刚刚我们提到的双向链表,另一个链是散列表中的拉链。前驱和后继指针是为了将结点串在双向链表中,hnext 指针是为了将结点串在散列表的拉链中。
哈希算法:
将任意长度的二进制值串映射为固定长度的二进制值串的算法。
应用:
- 安全加密(MD5/SHA/AES)
- 唯一标识
- 数据校验
- 散列函数
- 负载均衡(会话粘滞, 对IP或会话ID哈希)
- 数据分片(大文件关键词分片)
- 分布式存储(机器扩容导致重新计算哈希值,一致性哈希算法)