监控系统的设计
本文为个人对监控系统的设计调研后的总结及个人理解,如有偏差,欢迎指正。
监控系统是企业运维系统中非常重要的一环,一个强大成熟的监控系统,能够对所有业务系统的稳定运行提供保障。
功能模块 Link to heading
一个完整的监控系统,应该包含如下功能模块:
数据上报 Link to heading
监控的第一环,也就是监控指标的采集,在一个复杂的系统中,可能会有非常多的监控指标由不同种类的采集端进行采集,这时就需要有一个数据上报服务,所有采集端采集到的指标,统一上报到这个服务,再经由数据上报服务,对将数据提供给 tsdb、后端存储、告警判定等模块进行加工和消费。
一个好的数据上报模块,需要有标准化的灵活的数据模型,这样才能兼容大量的复杂的监控指标和采集方式,才能对后面的数据展示和告警策略配置提供更丰富的数据支持。以 open-falcon 为例,它采用和 opentsdb 相同的数据格式:metric、endpoint 加多组 key value tags,如下示例:
{
metric: load.1min,
endpoint: open-falcon-host,
tags: srv=falcon,idc=aws-sgp,group=az1,
value: 1.5,
timestamp: `date +%s`,
counterType: GAUGE,
step: 60
}
{
metric: net.port.listen,
endpoint: open-falcon-host,
tags: port=3306,
value: 1,
timestamp: `date +%s`,
counterType: GAUGE,
step: 60
}
这种多组 tag 的形式能够为数据提供更多维度的信息。需要注意的是,tag 的定义也需要有标准的规范,随意、不规范的 tag 定义,可能会给后续的存储组件造成极大的压力。
另外,还需考虑监控数据获取模式,一般有推和拉两种模式。
- 大部分已有监控平台如 open-falcon 都采用推模式。这种模式好处是实时性好,并且能够很容器的实现采集端的自动发现(只要起了采集的agent),采集到的数据直接推送给上报服务,但是缺点是对上报服务压力很大,全量的数据实时推送给上报服务,数据量大的时候很容易造成服务端压力过大,一般的解决方法是在前面加一个消息队列来作限流,减小服务端压力,但是同时也牺牲了部分的实时性。
- 典型的采用拉模式的获取数据的就是 prometheus。这种模式的好处是服务端可以很方便的配置自己需要拉取的数据,并提前知道自己所需要获取的数据量级,不易于出现意外的压力过大的情况,并且可以通过 联邦集群 的模式,来相对容易的实现压力分担和高可用。最大的缺点就是非实时性,采集到的信息的时间取决于 pull 的时间间隔。
最后,好的上报服务,还需考虑对采集端的支持,尽量通用并易于扩展。
数据存储 Link to heading
监控数据的存储,自己实现的话,成本和复杂度都很高,目前开源社区已经有很多成熟的产品,可以根据自己的需求进行选择。
首先,需要时序数据库来存储采集到的实时监控信息,并尽可能基于其功能支持可能的实时数据绘图功能,目前主流的选择有 prometheus, influxdb, opentsdb。
另外,还需根据需要选择存储监控信息归档数据的存储系统,实时信息数据量非常庞大,不可能全量存储,这是就需要对数据进行选择性的处理并归档存储。简单的可以选择基于 mysql/redis 等关系数据库加缓存的方式自己开发实现,贴近业务。数据量大、复杂的系统可以选在类似 elasticsearch 等搜索和数据分析引擎,来支持更复杂的需求和庞大的数据量。
仍以 open falcon 为例,选用了时序数据库 opentsdb,并自研了高性能数据存储、归档、查询组件 graph,采用 rrdtool 的数据归档策略,对实时数据进行采样、归档,存储到 graph 中,同时为了不丢失信息量,数据归档的时候,会按照平均值采样、最大值采样、最小值采样存三份。
告警 Link to heading
准确的告警判定,灵活的告警策略配置,以及丰富的告警渠道,是最终体现监控系统能力的最直接的方式。
告警判定,获取告警的规则配置和对应的监控数据,来判断是否需要告警,并通知相应的告警渠道来出发告警。视系统规模和场景而定,大规模复杂的系统,可以考虑借助消息队列等中间件,避免告警信息的丢失,更复杂的情况,可以参考一些开源规则引擎的实现,避免因判定阶段的效率低下,影响告警触发的及时性,同样可参考 open falcon 的 judge 模块。
策略配置,对于告警策略,要尽量灵活,结合多 tag 的数据模型,可以定制出非常灵活的告警策略。另外,对于告警级别,告警合并,告警抑制,告警恢复,告警升级的支持,在设计阶段都要考虑在内,策略配置的设计较为通用,有很多前人的经验可以直接借鉴,可以参考如 open falcon 的业界较为成熟的监控系统。
告警渠道,即发送告警的通道,常见的有邮件,IM(钉钉/企业微信等),短信,电话等,还要考虑
web hook 的支持,便于对接其他的系统。另外,告警渠道最好设计为可插拔易扩展的 plugin 模式,便于后续更多自定义渠道的添加。
dashboard 展示 (绘图) Link to heading
另一个直观体现监控平台能力的功能,就是绘图展示。监控采集的大量的数据,除了用于告警,用户不可能逐条查看,用户查看监控数据最主要的途径就是绘制监控图表。绘图能力,非常依赖数据储存,一般有实时信息图和历史信息图两种。
针对实时信息,一般直接从 tsdb 中获取数据直接进行绘图展示,这里对 tsdb 的性能及监控数据的数据模型都有很高的要求,tsdb 一般选择开源产品,对一般团队来说,能够优化的空间已经有限。而数据模型方面的优化,其实也相当重要。
例如,对于 influxDB 数据定义时的一个字段是定义成 tag 还是 field,对于后续的写入和读取性能,都有很大的影响;现在社区更加活跃的 prometheus,一个字段是否应该定义称 label,对性能的影响也很大,例如将一个值几乎不会重复的字段设为label,那么当数据量上来时,对性能的影响将非常严重,如果刚好对应的数据已经被多个系统所依赖,那么这种情况更加是灾难性的,所以,设计阶段将数据模型及规范设计好,是非常重要的一环。
针对历史信息,就需要从归档存储来读取信息。这里存储的性能,数据搜索和分析能力,归档采样的策略对历史信息的绘图能力都有很大的影响。对一般团队来说,这里比较需要关注的地方,一个是合适的存储的选型(自研的成本较高),另一个就是采样策略的选择,最简单的就是每隔一个固定时间段进行采样,为了避免极端数据,可以根据业务场景选取平均值/最大值/最小值采样。
另外,绘图作为使用频率最高的功能,设计上还需要尽可能用户友好,操作简单,可以加入考虑一些实用的小功能,如对比,分享等。
其他 Link to heading
监控的数据,如告警次数、资源使用率等,很有可能会作为部门运营分析数据的一部分,所以数据对于运营分析等其他系统的数据支持能力,也是可能需要考虑的一部分。
其他基础系统如发布平台/云管平台等可能和监控系统有所交互或影响的系统的对接。如云管平台下线虚拟机,如果监控平台不知情,就可能触发不必要的告警。
能力要求 Link to heading
基于以上功能模块,对于一个监控平台,有以下的基本的能力要求:
- 各个组件的水平扩展能力,保证每个组件的高可用,以及资源不足时可随时扩容
- 统一标准化数据模型
- 插件化的数据采集能力,基于标准化的数据模型,任意用户都可以自己开发扩展数据的采集端
- 灵活的告警配置和丰富的告警渠道
- 高性能的查询/绘图能力,这一能力同时要求了数据存储能力
- 外部系统数据及 API 支持
架构设计 Link to heading
open falcon 架构:
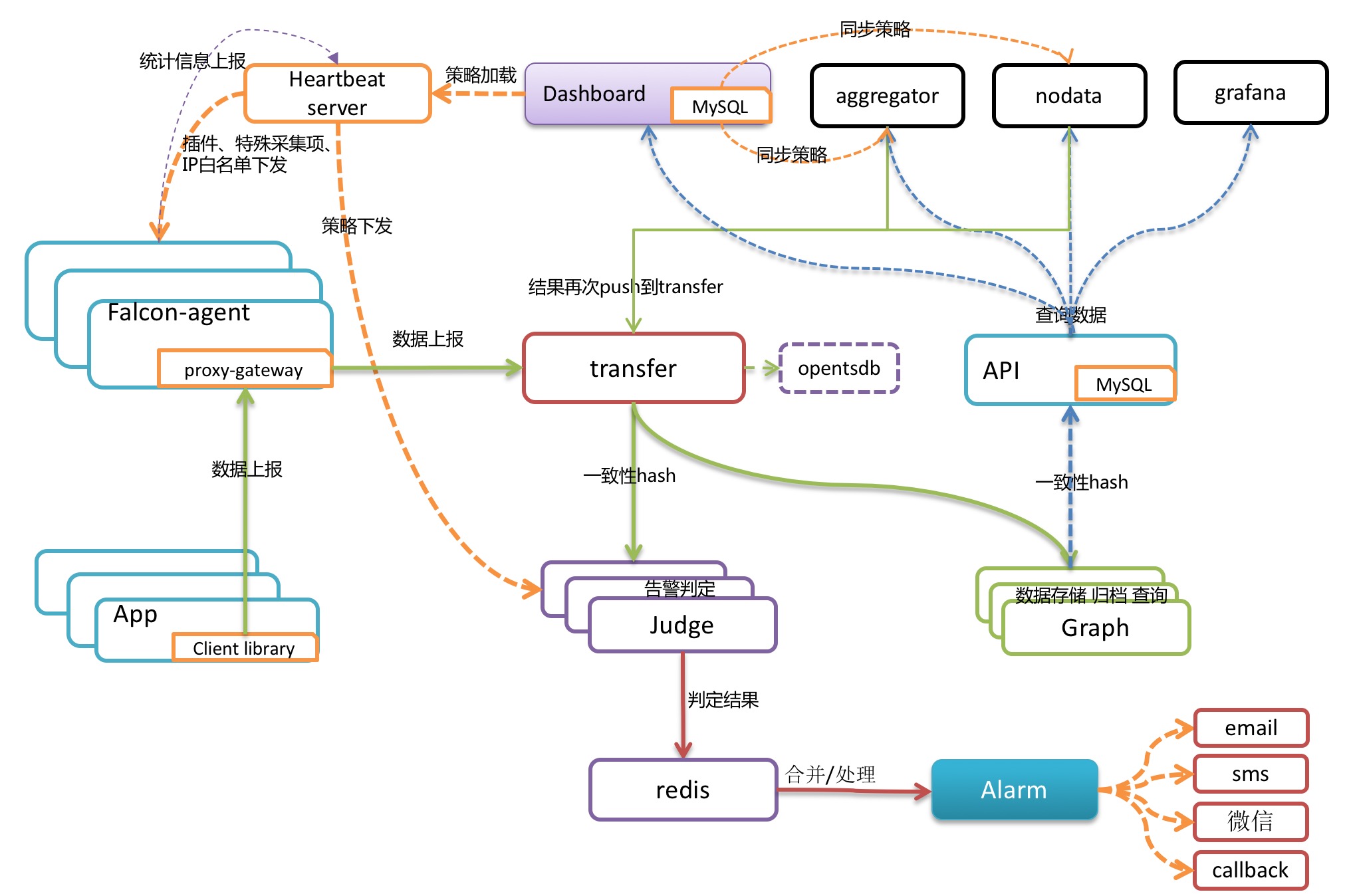
基本 open falcon 的架构已经基本满足一个复杂的监控系统所需要考虑的大部分因素,从头开始设计的话,可以参考 open falcon 的架构并结合自身业务场景进行设计。
对于规模没有那么大的团队,可按需合并或减少不分组件,并以一些更加活跃的开源产品替代其中自研的组件。当然,满足需求的话,完全可以直接使用 open falcon 作为监控平台。